

Is Maching Learning Clustering Used With Categorical Data
By Shelvi Garg, Data Scientist

In this web log we will explore and implement:
- 1-hot Encoding using:
- Python's category_encoding library
- Scikit-learn preprocessing
- Pandas' get_dummies
- Binary Encoding
- Frequency Encoding
- Label Encoding
- Ordinal Encoding
What is Categorical Data?
Categorical information is a type of data that is used to group information with like characteristics, while numerical data is a type of data that expresses information in the form of numbers.
Instance of chiselled data: gender
Why do we need encoding?
- Most automobile learning algorithms cannot handle chiselled variables unless we convert them to numerical values
- Many algorithm's performances even vary based upon how the chiselled variables are encoded
Categorical variables tin be divided into two categories:
- Nominal: no particular order
- Ordinal: there is some order betwixt values
Nosotros will as well refer to a crook sheet that shows when to use which type of encoding.
Method 1: Using Python's Category Encoder Library
category_encoders is an amazing Python library that provides fifteen dissimilar encoding schemes.
Here is the list of the fifteen types of encoding the library supports:
- One-hot Encoding
- Characterization Encoding
- Ordinal Encoding
- Helmert Encoding
- Binary Encoding
- Frequency Encoding
- Mean Encoding
- Weight of Evidence Encoding
- Probability Ratio Encoding
- Hashing Encoding
- Backward Difference Encoding
- Exit 1 Out Encoding
- James-Stein Encoding
- Yard-calculator Encoding
- Thermometer Encoder
Importing libraries:
import pandas as pd import sklearn pip install category_encoders import category_encoders as ce
Creating a dataframe:
data = pd.DataFrame({ 'gender' : ['Male', 'Female', 'Male', 'Female person', 'Female'], 'grade' : ['A','B','C','D','A'], 'metropolis' : ['Delhi','Gurugram','Delhi','Delhi','Gurugram'] }) information.head() 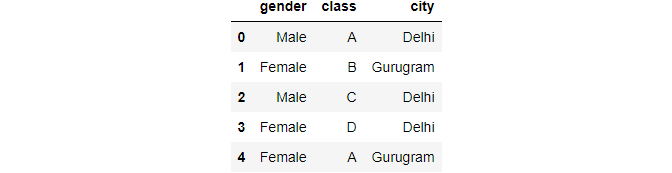
Paradigm By Author
Implementing i-hot encoding through category_encoder
In this method, each category is mapped to a vector that contains i and 0 denoting the presence or absenteeism of the feature. The number of vectors depends on the number of categories for features.
Create an object of the i-hot encoder:
ce_OHE = ce.OneHotEncoder(cols=['gender','city']) data1 = ce_OHE.fit_transform(data) data1.head()
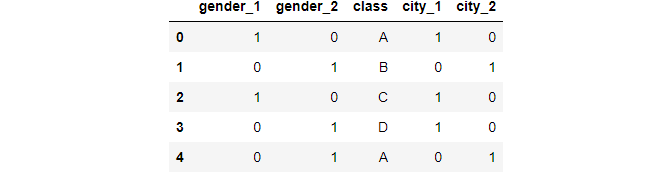
Image By Author
Binary Encoding
Binary encoding converts a category into binary digits. Each binary digit creates ane feature column.
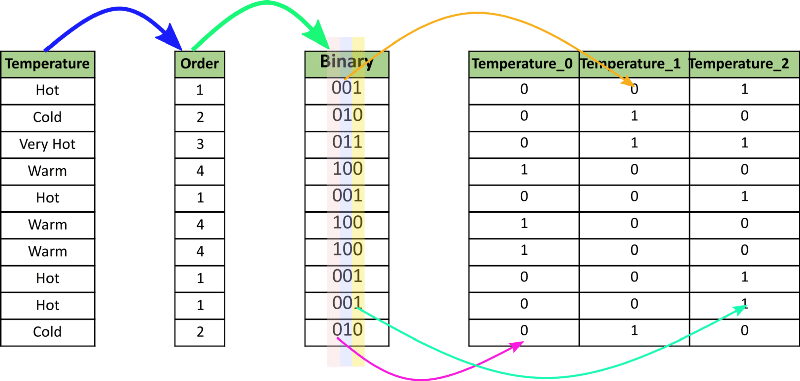
Prototype Ref
ce_be = ce.BinaryEncoder(cols=['course']); # transform the data data_binary = ce_be.fit_transform(data["form"]); data_binary
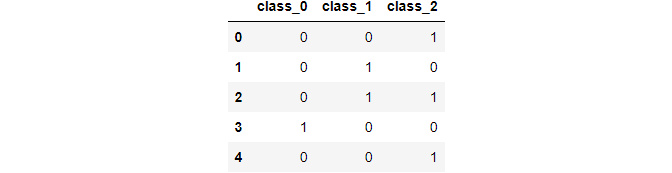
Prototype By Writer
Similarly, at that place are some other 14 types of encoding provided by this library.
Method 2: Using Pandas' go dummies
pd.get_dummies(data,columns=["gender","city"])
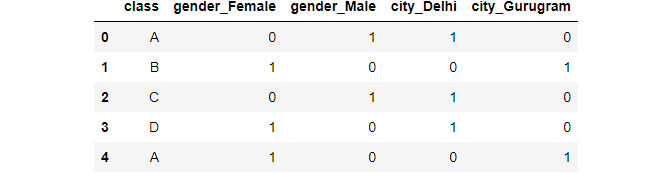
Image By Writer
Nosotros can assign a prefix if we want to, if we practise not want the encoding to use the default.
pd.get_dummies(data,prefix=["gen","city"],columns=["gender","metropolis"])
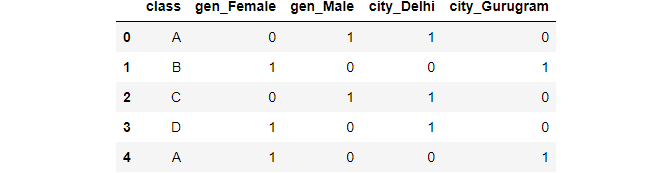
Prototype Past Writer
Method three: Using Scikit-learn
Scikit-larn also has 15 dissimilar types of congenital-in encoders, which can exist accessed from sklearn.preprocessing.
Scikit-learn 1-hot Encoding
Allow's start become the list of chiselled variables from our information:
southward = (data.dtypes == 'object') cols = listing(s[due south].index) from sklearn.preprocessing import OneHotEncoder ohe = OneHotEncoder(handle_unknown='ignore',sparse=False)
Applying on the gender column:
data_gender = pd.DataFrame(ohe.fit_transform(information[["gender"]])) data_gender

Image By Author
Applying on the city column:
data_city = pd.DataFrame(ohe.fit_transform(data[["city"]])) data_city

Image Past Writer
Applying on the class cavalcade:
data_class = pd.DataFrame(ohe.fit_transform(data[["class"]])) data_class
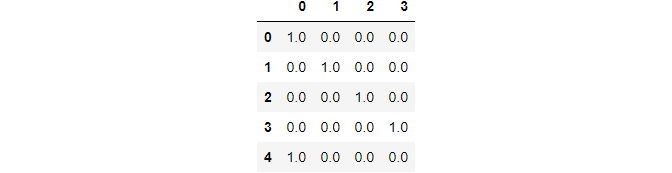
Image By Author
This is because the class cavalcade has four unique values.
Applying to the list of chiselled variables:
data_cols = pd.DataFrame(ohe.fit_transform(information[cols])) data_cols
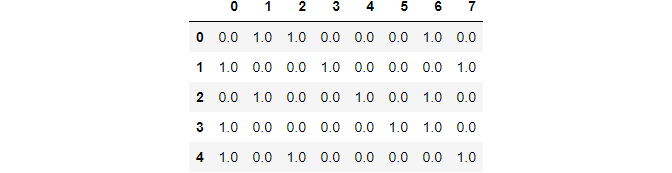
Image Past Author
Here the starting time 2 columns correspond gender, the side by side 4 columns represent class, and the remaining 2 stand for urban center.
Scikit-learn Characterization Encoding
In label encoding, each category is assigned a value from ane through Due north where North is the number of categories for the characteristic. There is no relation or society between these assignments.
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() Label encoder takes no arguments le_class = le.fit_transform(information[["class"]])
Comparing with ane-hot encoding
Image By Author
Ordinal Encoding
Ordinal encoding's encoded variables retain the ordinal (ordered) nature of the variable. It looks similar to characterization encoding, the only difference being that label coding doesn't consider whether a variable is ordinal or not; it volition then assign a sequence of integers.
Example: Ordinal encoding volition assign values every bit Very Good(1) < Good(2) < Bad(3) < Worse(4)
Get-go, we need to assign the original order of the variable through a lexicon.
temp = {'temperature' :['very cold', 'cold', 'warm', 'hot', 'very hot']} df=pd.DataFrame(temp,columns=["temperature"]) temp_dict = {'very common cold': one,'cold': 2,'warm': 3,'hot': 4,"very hot":5} df 
Image By Author
Then we can map each row for the variable every bit per the lexicon.
df["temp_ordinal"] = df.temperature.map(temp_dict) df
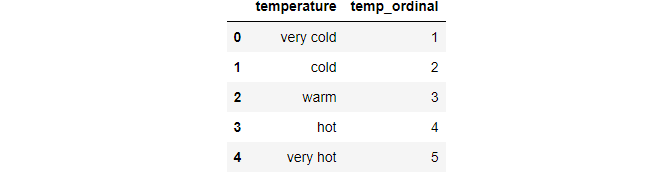
Image By Author
Frequency Encoding
The category is assigned as per the frequency of values in its full lot.
data_freq = pd.DataFrame({'class' : ['A','B','C','D','A',"B","E","E","D","C","C","C","E","A","A"]}) Grouping by class cavalcade:
iron = data_freq.groupby("course").size() Dividing past length:
Mapping and rounding off:
data_freq["data_fe"] = data_freq["class"].map(fe_).round(ii) data_freq

Paradigm By Writer
In this article, we saw 5 types of encoding schemes. Similarly, there are ten other types of encoding which we have non looked at:
- Helmert Encoding
- Hateful Encoding
- Weight of Evidence Encoding
- Probability Ratio Encoding
- Hashing Encoding
- Backward Departure Encoding
- Leave One Out Encoding
- James-Stein Encoding
- Yard-estimator Encoding
- Thermometer Encoder
Which Encoding Method is Best?
In that location is no single method that works best for every problem or dataset. I personally think that the get_dummies method has an advantage in its ability to be implemented very easily.
If you want to read about all 15 types of encoding, here is a very good article to refer to.
Here is a cheat sheet on when to use what type of encoding:
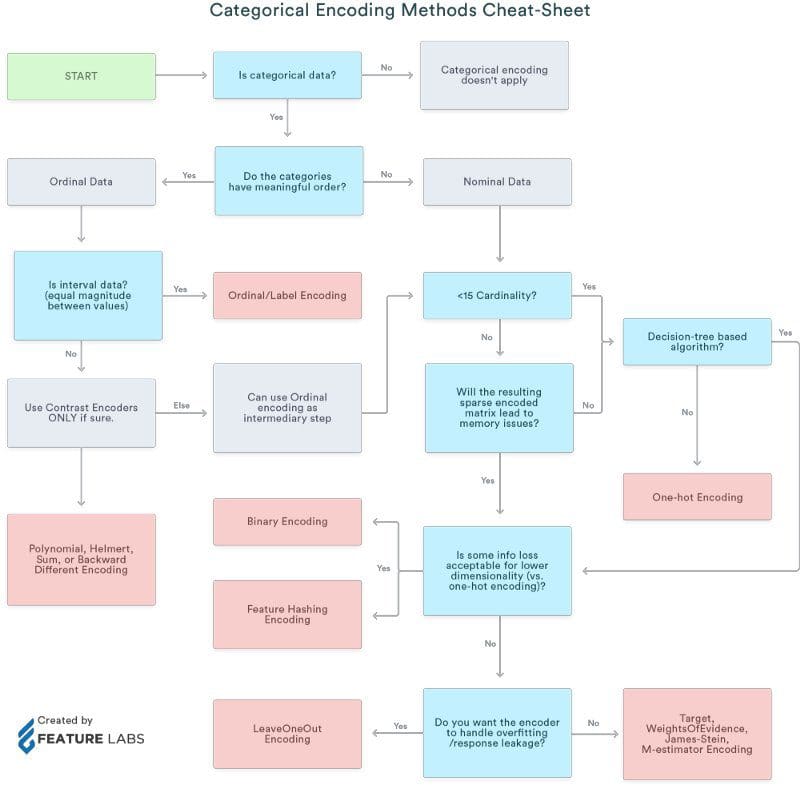
Prototype Ref
References:
- https://towardsdatascience.com/all-about-categorical-variable-encoding-305f3361fd02
- https://pypi.org/project/category-encoders/
- https://pandas.pydata.org/docs/reference/api/pandas.get_dummies.html
Bio: Shelvi Garg is a Data Scientist. Interests and learnings are not limited.
Related:
- Animated Bar Chart Races in Python

Source: https://www.kdnuggets.com/2021/05/deal-with-categorical-data-machine-learning.html
Posted by: andersoncritaiment.blogspot.com

0 Response to "Is Maching Learning Clustering Used With Categorical Data"
Post a Comment